Work
Here are some works of mine 📚
Publications
JuniperLiu at CoMeDi Shared Task: Models as Annotators in Lexical Semantics Disagreements
CoMeDi workshop
In this paper, we present the results of our system for the CoMeDi Shared Task, which predicts majority votes (Subtask 1) and annotator disagreements (Subtask 2).
We present the results of our system for the CoMeDi Shared Task, which predicts majority votes (Subtask 1) and annotator disagreements (Subtask 2). Our approach combines model ensemble strategies with MLP-based and threshold-based methods trained on pretrained language models. Treating individual models as virtual annotators, we simulate the annotation process by designing aggregation measures that incorporate continuous relatedness scores and discrete classification labels to capture both majority and disagreement. Additionally, we employ anisotropy removal techniques to enhance performance. Experimental results demonstrate the effectiveness of our methods, particularly for Subtask 2. Notably, we find that standard deviation on continuous relatedness scores among different model manipulations correlates with human disagreement annotations compared to metrics on aggregated discrete labels.A Top-down Graph-based Tool for Modeling Classical Semantic Maps: A Crosslinguistic Case Study of Supplementary Adverbs
NAACL 2025
In this paper, we propose a novel algorithm to automatically construct conceptual space and semantic map models.
Semantic map models (SMMs) construct a network-like conceptual space from cross-linguistic instances or forms, based on the connectivity hypothesis. This approach has been widely used to represent similarity and entailment relationships in cross-linguistic concept comparisons. However, most SMMs are manually built by human experts using bottom-up procedures, which are often labor-intensive and time-consuming. In this paper, we propose a novel graph-based algorithm that automatically generates conceptual spaces and SMMs in a top-down manner. The algorithm begins by creating a dense graph, which is subsequently pruned into maximum spanning trees, selected according to metrics we propose. These evaluation metrics include both intrinsic and extrinsic measures, considering factors such as network structure and the trade-off between precision and coverage. A case study on cross-linguistic supplementary adverbs demonstrates the effectiveness and efficiency of our model compared to human annotations and other automated methods.[Paper] [PPT in Chinese] [CODE] [PPT in English] [Poster]
How well do distributed representations convey contextual lexical semantics: a Thesis Proposal
Arxiv
In this thesis, our objective is to examine the efficacy of distributed representations from NNs in encoding lexical meaning.
Modern neural networks (NNs), trained on extensive raw sentence data, construct distributed representations by compressing individual words into dense, continuous, high-dimensional vectors. These representations are specifically designed to capture the varied meanings, including ambiguity, of word occurrences within context. In this thesis, our objective is to examine the efficacy of distributed representations from NNs in encoding lexical meaning. Initially, we identify four sources of ambiguity - homonymy, polysemy, semantic roles, and multifunctionality - based on the relatedness and similarity of meanings influenced by context. Subsequently, we aim to evaluate these sources by collecting or constructing multilingual datasets, leveraging various language models, and employing linguistic analysis tools.[Paper]
Fantastic Semantics and Where to Find Them: Investigating Which Layers of Generative LLMs Reflect Lexical Semantics
Findings of ACL 2024
In this paper, we specifically investigate the bottom-up evolution of lexical semantics for a popular LLM, namely Llama2, by probing its hidden states at the end of each layer using a contextualized word identification task. Our experiments show that the representations in lower layers encode lexical semantics, while the higher layers, with weaker semantic induction, are responsible for prediction.
Large language models have achieved remarkable success in general language understanding tasks. However, as a family of generative methods with the objective of next token prediction, the semantic evolution with the depth of these models are not fully explored, unlike their predecessors, such as BERT-like architectures. In this paper, we specifically investigate the bottom-up evolution of lexical semantics for a popular LLM, namely Llama2, by probing its hidden states at the end of each layer using a contextualized word identification task. Our experiments show that the representations in lower layers encode lexical semantics, while the higher layers, with weaker semantic induction, are responsible for prediction. This is in contrast to models with discriminative objectives, such as mask language modeling, where the higher layers obtain better lexical semantics. The conclusion is further supported by the monotonic increase in performance via the hidden states for the last meaningless symbols, such as punctuation, in the prompting strategy.
Ambiguity Meets Uncertainty: Investigating Uncertainty Estimation for Word Sense Disambiguation
Findings: ACL 2023
Word sense disambiguation (WSD), which aims to determine an appropriate sense for a target word given its context, is crucial for natural language understanding. Existing supervised methods treat WSD as a classification task and have achieved remarkable performance.
Word sense disambiguation (WSD), which aims to determine an appropriate sense for a target word given its context, is crucial for natural language understanding. Existing supervised methods treat WSD as a classification task and have achieved remarkable performance. However, they ignore uncertainty estimation (UE) in the real-world setting, where the data is always noisy and out of distribution. This paper extensively studies UE on the benchmark designed for WSD. Specifically, we first compare four uncertainty scores for a state-of-the-art WSD model and verify that the conventional predictive probabilities obtained at the end of the model are inadequate to quantify uncertainty. Then, we examine the capability of capturing data and model uncertainties by the model with the selected UE score on well-designed test scenarios and discover that the model reflects data uncertainty satisfactorily but underestimates model uncertainty. Furthermore, we explore numerous lexical properties that intrinsically affect data uncertainty and provide a detailed analysis of four critical aspects: the syntactic category, morphology, sense granularity, and semantic relations.Show, Tell and Rephrase: Diverse Video Captioning via Two-Stage Progressive Training
TMM 2022
Describing a video using natural language is an inherently one-to-many translation task. To generate diverse captions, existing VAE-based generative models typically learn factorized latent codes via one-stage training merely from stand-alone video-caption pairs. However, such a paradigm neglects set-level relationships among captions from the same video, not fully capturing the underlying multimodality of the generative process.
Describing a video using natural language is an inherently one-to-many translation task. To generate diverse captions, existing VAE-based generative models typically learn factorized latent codes via one-stage training merely from stand-alone video-caption pairs. However, such a paradigm neglects set-level relationships among captions from the same video, not fully capturing the underlying multimodality of the generative process. To overcome this shortcoming, we leverage neighbouring descriptions for the same video that are articulated with noticeable topics and language variations (i.e., paraphrases). To this end, we propose a novel progressive training method by decomposing the learning of latent variables into two stages that are topic-oriented and paraphrase-oriented, respectively. Specifically, the model learns from divergent topic sentences obtained by semantic-based clustering in the first stage. It is then trained again through paraphrases with a cluster-aware adaptive regularization, allowing more intra-cluster variations. Furthermore, we introduce an overall metric DAUM, a D iversity- A ccuracy U nified M etric to consider both the precision of the generated caption set and its coverage on the reference set, which has proved to have a higher correlation with human judgment than previous precision-only metrics. Extensive experiments on three large-scale video datasets show that the proposed training strategy can achieve superior performance in terms of accuracy, diversity, and DAUM over several baselines.Projects
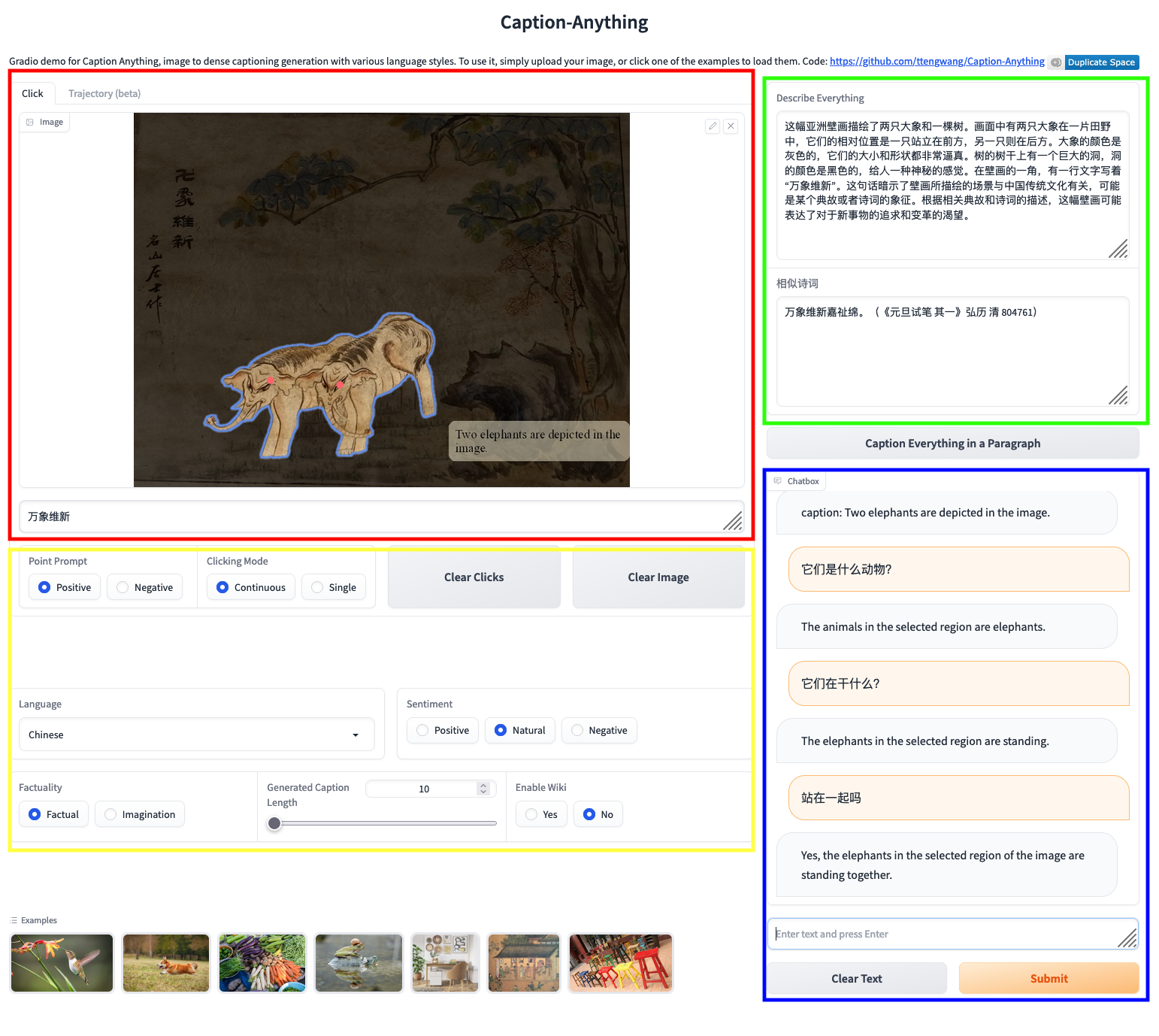
In this project, we have developed an application that automatically generates captions for the murals created during the Qing Dynasty. Additionally, users can engage with a chatbot to discuss specific aspects of these images. Our aim is to enhance the educational and artistic appeal of the artwork, thereby attracting a younger audience.
In this project, we have developed an application to automatically generate semantic map models given form-meaning tables. The maps are created by our proposed top-town approach and can be interactively visualized, including editing, searching, merging, downloading among others. For more details, please refer to this technical report. We also invite typological linguists to help us test this application by referring to the guidance.